Check out the whole project on GitHub: https://github.com/MayADevBe/Swedish-FrequencyList-8Sidor
I recently decided to do a fun weekend project, combining two of my interests. The first is programming with a special interest in Data Mining and Natural Language Processing (NLP). The second is Language Learning - specifically, I recently started learning Swedish.
One part of my method for learning languages is learning the most frequent words of the language. So I decided to create my own list.
During my research for finding good resources for texts in Swedish, I found https://8sidor.se/. 8Sidor is a website with short, easy news articles in Swedish. I chose this as my textbase for extracting my word list.
I split this into a series of two articles. The first and will be about the Data Mining part of the project, how I extracted the links and articles from the website. The goal is to extract the text of the articles from the website to gather a data set.
This data set will then be used in the second part of the project that deals with NLP.
Data Source
Since, for this short project, 8Sidor is my only source, the domain of the text might influence the words in the list. As I mentioned, the articles are written in easy Swedish, so I assume that the used words are very basic. However, since these frequency lists are used as a start batch of words to learn the language, this looks exactly what I want.
On the other hand, there might be some specific categories predominating that might not generally be used in another context, like Sport and Crime. Since I wanted to use the list to prepare a general, broad knowledge of Swedish words and to understand the articles on the website, this was no problem for me.
Website Structure
The first step for Data Mining is taking a closer look at the website and its structure. Specifically, of the parts of the website that give an overview of articles leading to the links to all the articles and the contents of the articles.
Link Structure
Looking at the website, I can see different categories in the navigation bar. These are the different categories for the articles.

When clicking on one of these categories, I can see the structure of these pages. The structure of the links is: https://8sidor.se/kategori/\<category\>/. And on the bottom of the page, I can see a paginator, which helps me figure out how I can iterate over all article links. The structure is the following: https://8sidor.se/kategori/\<category\>/page/\<number\>/.
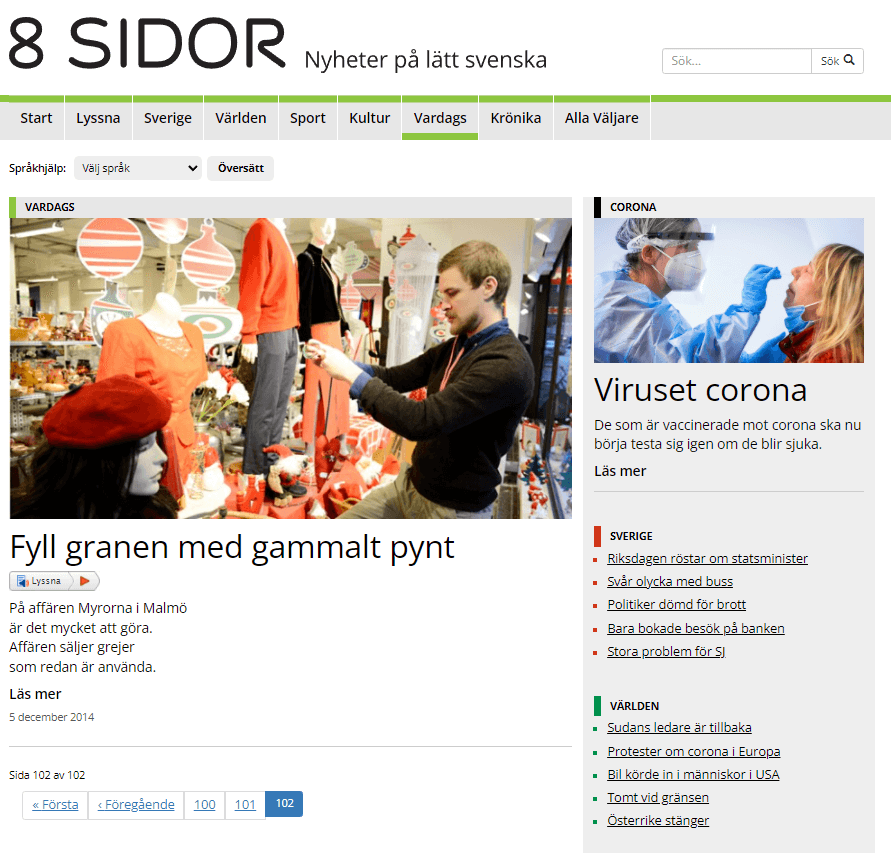 https://8sidor.se/kategori/vardags/page/102/
https://8sidor.se/kategori/vardags/page/102/
Category Pages
When looking at the source code - that can be accessed with F12, I can find the HTML elements that contain the links to the articles. Knowing this, I can extract these links to get to the pages of the articles.
To find the correct HTML Element easily, I can use the ‘Inspect’ cursor, which can be accessed on the upper left corner of the source viewer. This will outline the HTML elements when hovering over/clicking on it. When clicking on a headline of an article (which is simultaneously the link to this article) the source viewer shows the part of the HTML code with the element and its characteristics (for example the classes).
I can see that each article has a picture, headline, summary, date and so on. They are an article element with an ‘article’ class. And the link from the headline I want to extract is an a inside an h2 tag.
It looks something like this (when minimizing/ignoring the irrelevant elements).
| |
Article Pages
Now that I can get the links to the articles, I can look at the article pages. The focus here is to extract the title and the content.
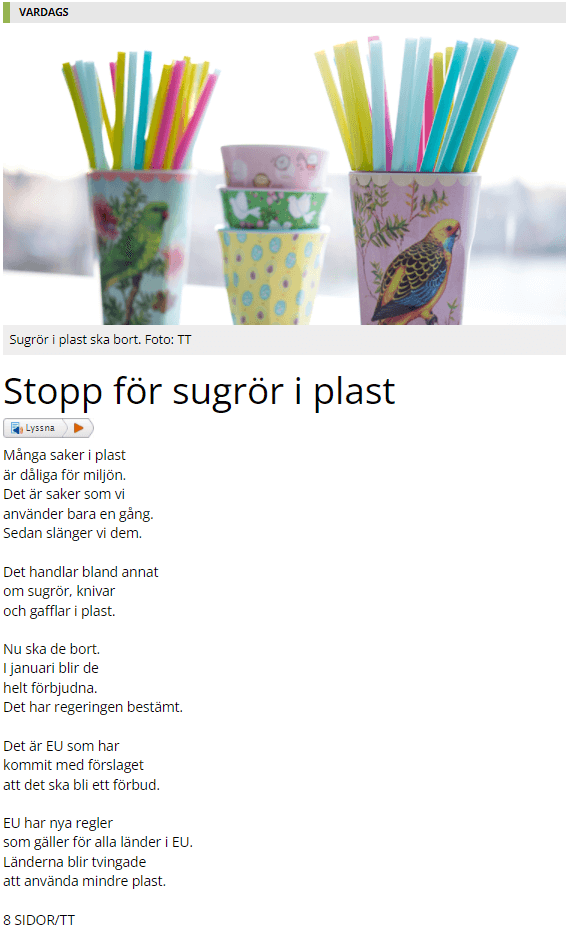 https://8sidor.se/vardags/2021/11/stopp-for-sugror-i-plast/
https://8sidor.se/vardags/2021/11/stopp-for-sugror-i-plast/
The headline can be found within the h1 tag and the content in a div element with a ‘content’ class.
| |
This div element has some more elements that I mostly ignored because I was only interested in the text. The thing to be aware of is that some of these elements contained text like ‘8 SIDOR/TT’ and ‘Lyssna’ - this might need to be cleaned in a later step.
Programming
Now, let’s talk about extraction. For Data Mining, I first extracted the links for the article pages, then I extracted the HTML of the article and saved the article content I needed.
To write the program I used Python because it is easy to use, I have experience with it and it has simple libraries for Data Mining and Natural Language Processing.
General Considerations
Before I start explaining the actual code, I wanted to talk about a few considerations that I thought about and implemented.
Batches
With most things regarding Data Mining, I am dealing with a considerable amount of data. To make this more manageable, I decided to do the mining in batches. My main reasons were:
- Saving all the links/articles in one file would be very convoluted.
- This way I could also better control the amounts of requests that were sent.
- Finally, this is a way of making sure if the program crashes for whatever reason, I only lose the last batch.
- Additionally, it makes it possible to not start the program from the beginning but from a specific batch.
JSON
Next, I thought about how to save the data. I could have used a database. However, I felt for a weekend project, that would take up too much time. Especially because I have no experience with databases in Python.
Instead, I decided to save the data in files in JSON format. I already had some experience and wanted to refresh this. Additionally, it makes it a lot faster to take a look at the data (especially on Github).
Sleep
Since mining data from a lot of articles per category would lead to a lot of requests to the website, I decided to add a small waiting time after each request. This will make the code a lot slower. However, I was not sure about the underlying technology. Generally, I would assume that these requests are still only a fraction of the visits the website’s servers can handle. However, I did not want to risk potentially being banned from the website or causing any harm.
Libraries
For the Data Mining part I used four libraries - as you can see from the code snippet below:
| |
- The requests library, as the name suggests, is used to send the HTML request to the website and return the server response of the HTTP request.
- BeautifulSoup is then used to parse the HTML response. This makes it easier to find specific HTML elements.
- The time library is simply used to let the program sleep (which means the program waits and does not do anything during that time).
- The JSON library, as mentioned before, allows the transformation between Python objects and JSON objects, which makes loading and saving the data in JSON text files easy.
Links
Now let’s take a look at the resulting code. I will explain the most important parts. If you want to check out the whole code head over to the GitHub project.
The first step, as already mentioned, is the extraction of the links to the articles.
First, I implemented the pagination link structure that I explained in the ‘Link Structure’ paragraph.
I use a variable called
kategoryfor the pagination link because the link structure is the same for each category.iis a variable that defines what page of the paginator we want to look at. Generally, this should start from 1 but because of the batches, it might also be any other value. Also, because of the implementation of the batches, I added an end-condition of the while loop.1 2 3 4 5 6 7 8 9 10def extract_article_links(kategory, startpage = 1, endpage = 100 ): i = startpage ... website = "https://8sidor.se/kategori/" + kategory + "/page/" ... while pagination_done == False and i<=endpage: ... r = requests.get(website + str(i) + "/") ... i += 1Then I used the requests library to get the response of the web page. The response has a lot of properties (if you want to know more check out the tutorial on w3schools). In this case, I, however, was only interested in the actual content - so the HTML of the page - which can be accessed through the
textproperty.1 2 3 4... r = requests.get(website + str(i) + "/") data = r.text ...Now that I had the HTML of the page, I used ‘BeautifulSoup’ with the HTML parser to better access the HTML tags.
First, I checked if I am at the end of the pagination. This could have also been done with the status_code of the request object. But I used the same method as in the ‘Website Structure’ paragraph to figure out, how a ‘NOT FOUND’ page looks like. It contains a
h2tag with the text ‘Sidan kunde inte hittas’ - ‘The page could not be found’. Thefindmethod looks for the specified HTML tag and returns the result with the tags. Since I compare only to text, I used.text, which returns only the content inside the tags.Next, I can extract the content in the same way - with the in the ‘Category Pages’ paragraph found structure. The wanted links are in the article tags that have a class called ‘article’. Additionally, I used the
find_allmethod, which returns a list of all the found elements instead of only one.Lastly, for each article tag, I then looked for the links in the same manner. Since the links are not inside the tags but in the property
href, I had to look for this instead of thetext.1 2 3 4 5 6 7 8 9 10 11 12 13 14... soup = BeautifulSoup(data, 'html.parser') ... h2_first = soup.find("h2").text if h2_first == "Sidan kunde inte hittas": pagination_done = True articles = soup.find_all("article", class_="article") # extract links for actual articles for article in articles: link = article.find("h2").find("a")['href'] article_links.append(link) ...Now that I extracted the list of links for the article, they have to be saved.
This is done by opening the file in which I want to save the links and then I can write them to the file. To make it easier in later parts, I wrote one link per line.
1 2 3 4 5 6... # write links to file: with open('links/sidor8_links' + "_" + kategory + '.txt', 'a', encoding='UTF-8' ) as f: for link in article_links: f.write(link + "\n") ...Lastly, as mentioned, I let the program sleep for a few seconds.
1 2 3 4SLEEP_TIME = 20 ... time.sleep(SLEEP_TIME) ...
Articles
With the links to the articles, the next step was to extract the actual content of the articles.
The first step is to read the previously collected links from the file and add them to a list.
1 2 3 4 5 6 7def extract_articles(kategory, start, end): links = [] with open('links/sidor8_links' + "_" + kategory + '.txt', 'r') as f: for position, line in enumerate(f): if position >= start and position <= end: links.append(line) ...Next, I extract the content of the articles for each link. These steps are very similar to the steps in the ‘Links’ paragraph.
- Send the request and get the HTML code
- Extract the headline and content with the ‘BeautifulSoup’ parser. The
get_textmethod is used because the div tag contains not just text but more tags. I saved the article data as a dictionary, so I can easily save it in JSON format. - After the request, I added another sleeping phase.
1 2 3 4 5 6 7 8 9 10 11 12def extract_article_content(link): ... r = requests.get(link) data = r.text soup = BeautifulSoup(data, 'html.parser') title = soup.find("h1").text text = soup.find("div", class_="content").get_text() article = {"link": link, "title": title, "text": text} time.sleep(SLEEP_TIME) return articleAgain, the last step is saving the intermediate result, meaning the articles. This is done by opening a file and using the
json.dumpswhich converts the python object (a list of dictionaries in this case) to JSON objects and writes these to the file.1 2 3... with open('articles/sidor8_articles_' + kategory + "_" + str(start) + "-" + str(end) + ".json", "w", encoding='UTF-8' ) as f: json.dump(articles, f, indent=3, ensure_ascii=False)
Result
I successfully extracted the content of articles from the 8Sidor website. With this, the first part of the project - Data Mining - is done. The second part - Natural Language Processing - will be described in a separate article.
Since I saved the extracted data in batches in different files, it led to a lot of files, which can get chaotic very fast. I cleaned it up by separating the files into folders.
The lists of links to articles of the site are separated into one file for each of the categories. For each category, I extracted 150 links, except for the category ‘svergie’ where I extracted 450 links. This could be built upon to get a bigger dataset due to limited time I decided these were enough for the project. The links can be found in the ’links’ folder of the GitHub project.
Here is an example of how the files look: sidor8_links_sverige.txt
| |
The files with article information are separated by category and batches. They contain the link, headline and content for each article. The files can be found in the ‘articles’ folder.
Here is an example of how the files look: sidor8_articles_kronika_1-50.json
| |
I hope my write-up of this project was helpful for you. If you have any questions, feel free to reach out. And check out the whole project on my GitHub: https://github.com/MayADevBe/Swedish-FrequencyList-8Sidor for the complete code and results.